Capítulo 3. Estructura y arquitectura de Cocoon
En este apartado me dedicaré a hablar un poco de la estructura interna y arquitectura en la que se basa Cocoon.
3.1. Conceptos claves
Antes de entrar en detalles es recomendable mostrar tres conceptos claves de la estructura de Cocoon. Éstos son:
- Pipeline(o tubería)
La idea es dividir el procesamiento de un documento XML en varios pasos más elementales. Un pipeline consiste en una entrada seguida de un conjunto de procesos de tratado de la entrada y una salida. Realmente es un concepto muy sencillo pero a la vez muy potente y hace que la programación sea más fácil y más escalable.
- Componentes del Pipeline
Son los que se encargan de llevar a cabo una tarea en particular en el pipeline como generar un documento XML, aplicar una transformación o producir una salida, entre otros. Estos componentes se pueden personalizar y pueden ser creados por el propio desarrollador.
Existen cuatro grupos generales de componentes. Éstos son:
- Entradas del Pipeline
Son los generadores y los lectores (Ver Sección 3.1.1) .
- Procesadores
Son los que llevan a cabo las transformaciones y las acciones (Ver Sección 3.1.1).
- Salidas del Pipeline
Son los serializadores (Ver Sección 3.1.1).
- Procesamiento Condicional
Es la parte encargada de hacer las selecciones y el proceso de match (Sección 7.1.1)
- Atender una solicitud
Esto incluye una serie de pasos, como identificar de forma selectiva el pipeline correcto que debe atender la solicitud pedida, cerciorarse de que el pipeline se lleve a cabo y producir el resultado al cliente que hizo la solicitud.
3.1.1. Estructura
Estructuralmente hablando Cocoon está compuesto de:
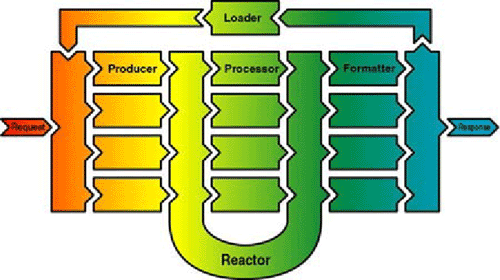
- Productores
Son los ficheros fuentes de donde proviene el XML. Estos pueden ser estáticos o dinámicos (es decir creados mediante XSP). La operación de un productor se basa en transformar los datos del fichero en eventos SAX.
- Procesadores
Atrapan el XML de los productores para aplicarle diversos procesos, como por ejemplo hacer conectividad a una base de datos, aplicar transformaciones XSL a los documentos XML, convertir los XSP en clases Java, etc. Son el proceso principal del Pipeline. El más común es el transformador XSLT
Cuando de contenido dinámico se habla, entran las acciones, es decir, procesos que sólo se pueden llevar a cabo y de los que sólo se puede saber el resultado en tiempo de producción, tales como interacción con bases de datos, validaciones, envío de correo electrónico, etc.
- Reactor
Es la central estructural. Extrae del XML del productor, las instrucciones para determinar qué procesadores actuarán en el documento.
- Formateadores
Son el punto final en un Pipeline. Recogen la representación interna del XML resultante (que está dada en eventos SAX) y la preparan para enviar como respuesta al cliente en el formato adecuado.
El formateador o serializador más común es el serializador XML que simplemente obtiene los eventos SAX y los lleva a un documento XML.
La anterior información se puede apreciar con el siguiente gráfico.
3.1.2. Arquitectura
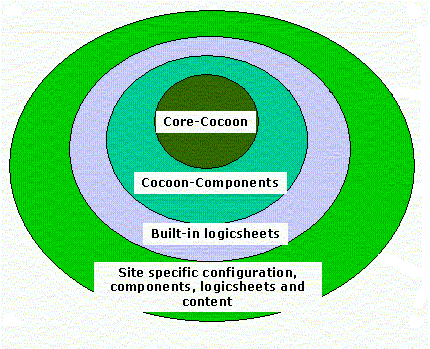
- Core Cocoon
Es el corazón de Cocoon. Encontramos un entorno para el control de sesiones, ficheros para configuración de Cocoon, para hacer manejo de contextos, aplicar mecanismos de caché, Pipeline, generación, compilación, carga y ejecución de programas.
- Cocoon Components
En esta capa encontramos los generadores de XML, transformadores de XML, matchers de ficheros y serializadores para formatear los ficheros.
- Built-in Logicsheets
Son hojas lógicas que necesita Cocoon para ficheros como sitemap, xsp, esql, request, response.
- Site specific configuration, components, logicsheets and content
Es el nivel más externo en el cual un desarrollador puede hacer configuración, creación de componentes, creación de hojas lógicas y contenido definido por el usuario de Cocoon para su aplicación